
现如今的互联网应用大都是采用 分布式系统架构 设计的,所以 消息队列 已经逐渐成为企业应用系统 内部通信 的核心手段,
它具有 低耦合、可靠投递、广播、流量控制、最终一致性 等一系列功能。
当前使用较多的 消息队列 有 RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ 等,而部分数据库 如 Redis、MySQL 以及 phxsql ,如果硬搞的话,其实也可实现消息队列的功能。
可能有人觉得,各种开源的 MQ 已经足够使用了,为什么需要用 Redis 实现 MQ 呢?
- 有些简单的业务场景,可能不需要重量级的 MQ 组件(相比 Redis 来说,Kafka 和 RabbitMQ 都算是重量级的消息队列)
那你有考虑过用 Redis 做消息队列吗?
这一章,我会结合消息队列的特点和 Redis 做消息队列的使用方式,以及实际项目中的使用,来和大家探讨下 Redis 消息队列的方案。
一、回顾消息队列
消息队列 是指利用 高效可靠 的 消息传递机制 进行与平台无关的 数据交流,并基于数据通信来进行分布式系统的集成。
通过提供 消息传递 和 消息排队 模型,它可以在 分布式环境 下提供 应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步 等等功能,其作为 分布式系统架构 中的一个重要组件,有着举足轻重的地位。
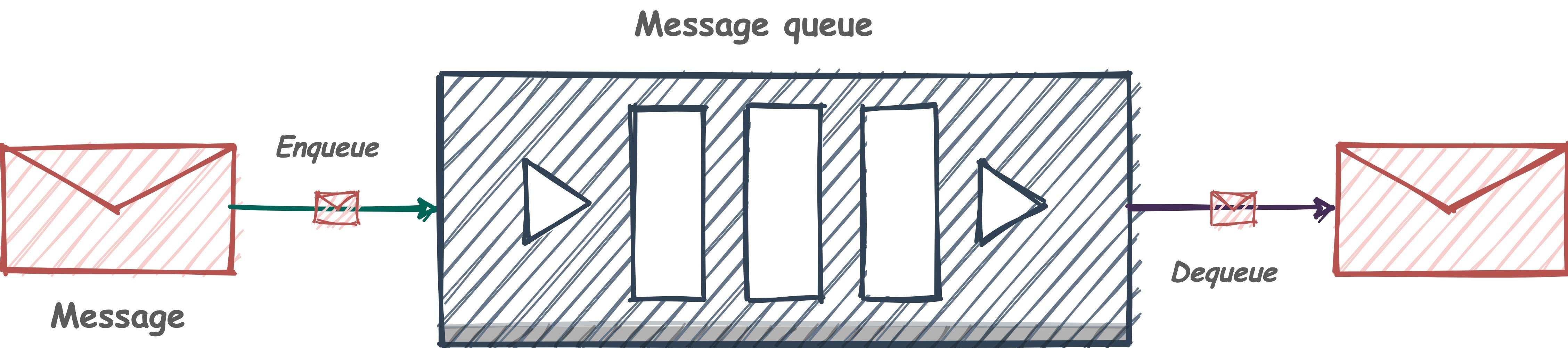
现在回顾下,我们使用的消息队列,一般都有什么样的特点:
- 三个角色:生产者、消费者、消息处理中心
- 异步处理模式:生产者 将消息发送到一条 虚拟的通道(消息队列)上,而无须等待响应。消费者 则 订阅 或是 监听 该通道,取出消息。两者互不干扰,甚至都不需要同时在线,也就是我们说的 松耦合
- 可靠性:消息要可以保证不丢失、不重复消费、有时可能还需要顺序性的保证
撇开我们常用的消息中间件不说,你觉得 Redis 的哪些数据类型可以满足 MQ 的常规需求~~
二、Redis 实现消息队列
思来想去,只有 List 和 Streams 两种数据类型,可以实现消息队列的这些需求,当然,Redis 还提供了发布、订阅(pub/sub) 模式。
我们逐一看下这 3 种方式的使用和场景。
2.1 List 实现消息队列
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
所以常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 Redis 的列表,另一个线程从这个列表中轮询数据进行处理。
Redis 提供了好几对 List 指令,先大概看下这些命令,混个眼熟
List 常用命令
| 命令 | 用法 | 描述 | 示例 |
|---|---|---|---|
| LPUSH | LPUSH key value [value …] | 将一个或多个值 value 插入到列表 key 的表头如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表头 | 正着进反着出 |
| LPUSHX | LPUSHX key value | 将值 value 插入到列表 key 的表头,当且仅当 key 存在并且是一个列表。和 LPUSH 命令相反,当 key 不存在时, LPUSHX 命令什么也不做 | |
| RPUSH | RPUSH key value [value …] | 将一个或多个值 value 插入到列表 key 的表尾(最右边) | 怎么进怎么出 |
| RPUSHX | RPUSHX key value | 将值 value 插入到列表 key 的表尾,当且仅当 key 存在并且是一个列表。和 RPUSH 命令相反,当 key 不存在时, RPUSHX 命令什么也不做。 | |
| LPOP | LPOP key | 移除并返回列表 key 的头元素。 | |
| BLPOP | BLPOP key [key …] timeout | 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 | |
| RPOP | RPOP key | 移除并返回列表 key 的尾元素。 | |
| BRPOP | BRPOP key [key …] timeout | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 | |
| BRPOPLPUSH | BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 | |
| RPOPLPUSH | RPOPLPUSH source destinationb | 命令 RPOPLPUSH 在一个原子时间内,执行以下两个动作:将列表 source 中的最后一个元素(尾元素)弹出,并返回给客户端。将 source 弹出的元素插入到列表 destination ,作为 destination 列表的的头元素 | RPOPLPUSH list01 list02 |
| LSET | LSET key index value | 将列表 key 下标为 index 的元素的值设置为 value | |
| LLEN | LLEN key | 返回列表 key 的长度。如果 key 不存在,则 key 被解释为一个空列表,返回 0 .如果 key 不是列表类型,返回一个错误 | |
| LINDEX | LINDEX key index | 返回列表 key 中,下标为 index 的元素。下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。 | |
| LRANGE | LRANGE key start stop | 返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定 | |
| LREM | LREM key count value | 根据参数 count 的值,移除列表中与参数 value 相等的元素 | |
| LTRIM | LTRIM key start stop | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 | |
| LINSERT | LINSERT key BEFORE|AFTER pivot value | 将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。当 pivot 不存在于列表 key 时,不执行任何操作。当 key 不存在时, key 被视为空列表,不执行任何操作。如果 key 不是列表类型,返回一个错误。 | LINSERT list01 before c++ c#(在c++之前加上C#) |
挑几个弹入、弹出的命令就可以组合出很多姿势
LPUSH、RPOP 左进右出
RPUSH、LPOP 右进左出
127.0.0.1:6379> lpush mylist a a b c d e
(integer) 6
127.0.0.1:6379> rpop mylist
"a"
127.0.0.1:6379> rpop mylist
"a"
127.0.0.1:6379> rpop mylist
"b"
127.0.0.1:6379>

即时消费问题
通过 LPUSH,RPOP 这样的方式,会存在一个性能风险点,就是消费者如果想要及时的处理数据,就要在程序中写个类似 while(true) 这样的逻辑,不停的去调用 RPOP 或 LPOP 命令,这就会给消费者程序带来些不必要的性能损失。
所以,Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Bloking的都是阻塞式),客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。这种方式就节省了不必要的 CPU 开销。
LPUSH、BRPOP 左进右阻塞出
RPUSH、BLPOP 右进左阻塞出
127.0.0.1:6379> lpush yourlist a b c d
(integer) 4
127.0.0.1:6379> blpop yourlist 10
1) "yourlist"
2) "d"
127.0.0.1:6379> blpop yourlist 10
1) "yourlist"
2) "c"
127.0.0.1:6379> blpop yourlist 10
1) "yourlist"
2) "b"
127.0.0.1:6379> blpop yourlist 10
1) "yourlist"
2) "a"
127.0.0.1:6379> blpop yourlist 10
(nil)
(10.02s)
如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
因为 Redis 单线程的特点,所以在消费数据时,同一个消息会不会同时被多个 consumer 消费掉,但是需要我们考虑消费不成功的情况。
可靠队列模式 | ack 机制
以上方式中, List 队列中的消息一经发送出去,便从队列里删除。如果由于网络原因消费者没有收到消息,或者消费者在处理这条消息的过程中崩溃了,就再也无法还原出这条消息。究其原因,就是缺少消息确认机制。
为了保证消息的可靠性,消息队列都会有完善的消息确认机制(Acknowledge),即消费者向队列报告消息已收到或已处理的机制。
Redis List 怎么搞一搞呢?
再看上边的表格中,有两个命令, RPOPLPUSH、BRPOPLPUSH (阻塞)从一个 list 中获取消息的同时把这条消息复制到另一个 list 里(可以当做备份),而且这个过程是原子的。
这样我们就可以在业务流程安全结束后,再删除队列元素,实现消息确认机制。
127.0.0.1:6379> rpush myqueue one
(integer) 1
127.0.0.1:6379> rpush myqueue two
(integer) 2
127.0.0.1:6379> rpush myqueue three
(integer) 3
127.0.0.1:6379> rpoplpush myqueue queuebak
"three"
127.0.0.1:6379> lrange myqueue 0 -1
1) "one"
2) "two"
127.0.0.1:6379> lrange queuebak 0 -1
1) "three"
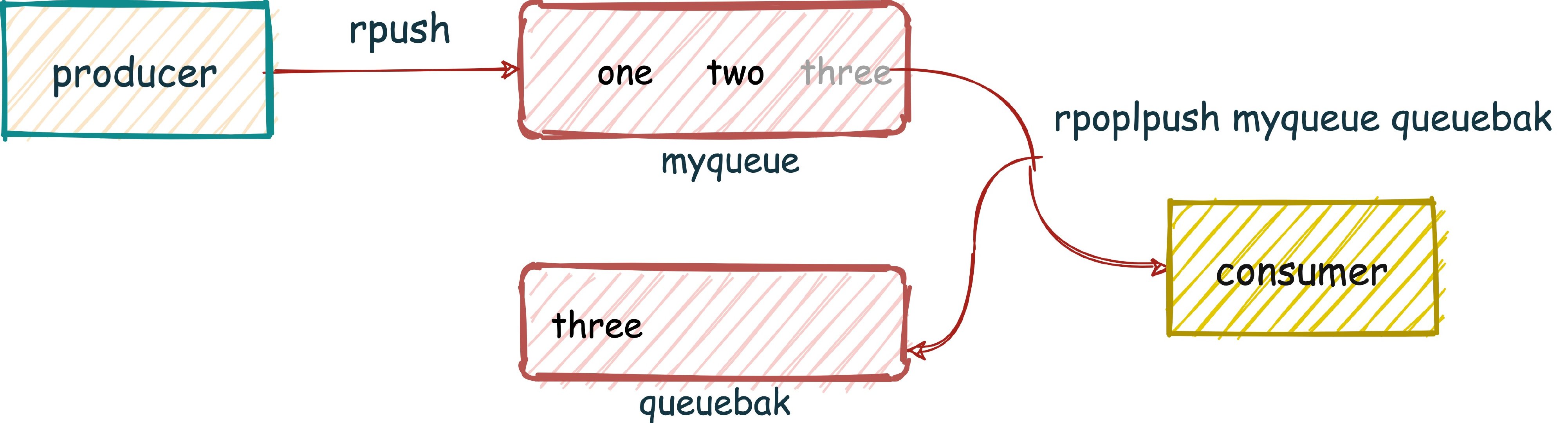
之前做过的项目中就有用到这样的方式去处理数据,数据标识从一个 List 取出后放入另一个 List,业务操作安全执行完成后,再去删除 List 中的数据,如果有问题的话,很好回滚。
当然,还有更特殊的场景,可以通过 zset 来实现延时消息队列,原理就是将消息加到 zset 结构后,将要被消费的时间戳设置为对应的 score 即可,只要业务数据不会是重复数据就 OK。
2.2 订阅与发布实现消息队列
我们都知道消息模型有两种
- 点对点: Point-to-Point(P2P)
- 发布订阅:Publish/Subscribe(Pub/Sub)
List 实现方式其实就是点对点的模式,下边我们再看下 Redis 的发布订阅模式(消息多播),这才是“根正苗红”的 Redis MQ
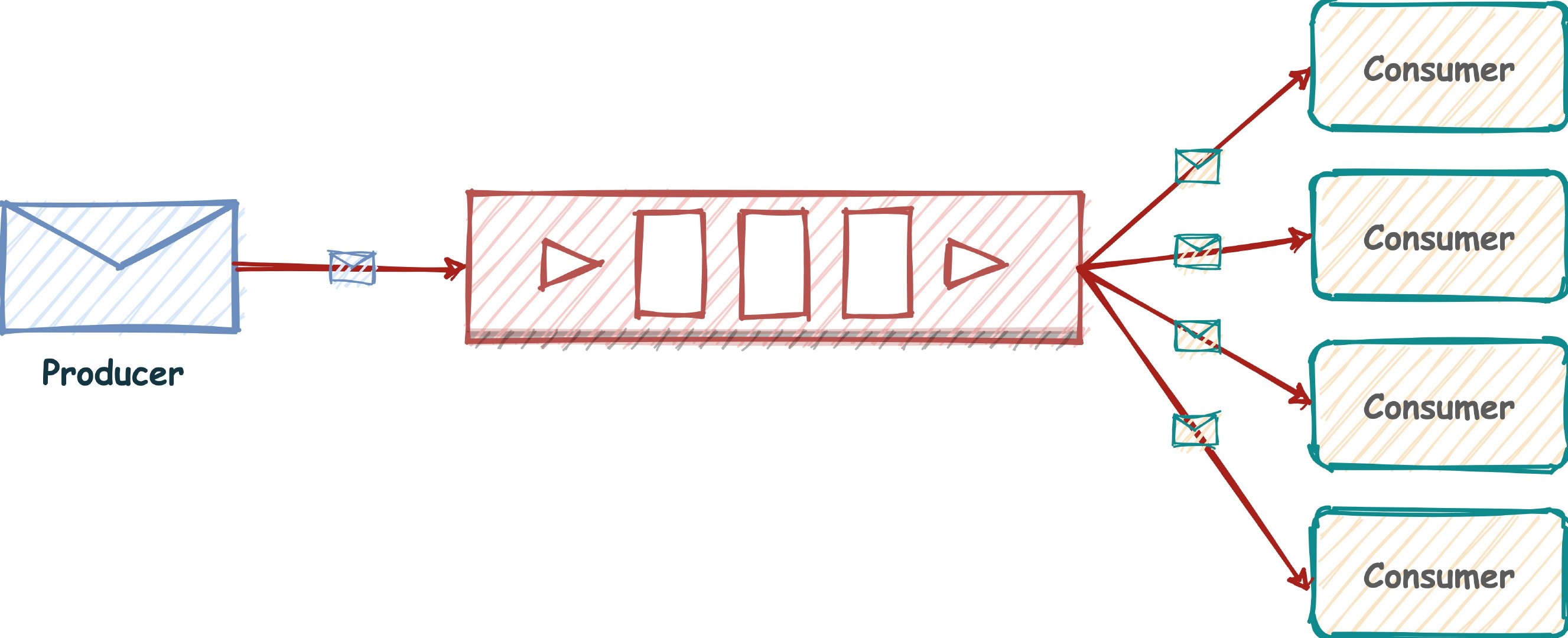
“发布/订阅”模式同样可以实现进程间的消息传递,其原理如下:
“发布/订阅”模式包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或者多个频道(channel),而发布者可以向指定的频道(channel)发送消息,所有订阅此频道的订阅者都会收到此消息。
Redis 通过 PUBLISH 、 SUBSCRIBE 等命令实现了订阅与发布模式, 这个功能提供两种信息机制, 分别是订阅/发布到频道和订阅/发布到模式。
这个 频道 和 模式 有什么区别呢?
频道我们可以先理解为是个 Redis 的 key 值,而模式,可以理解为是一个类似正则匹配的 Key,只是个可以匹配给定模式的频道。这样就不需要显式的去订阅多个名称了,可以通过模式订阅这种方式,一次性关注多个频道。
我们启动三个 Redis 客户端看下效果:

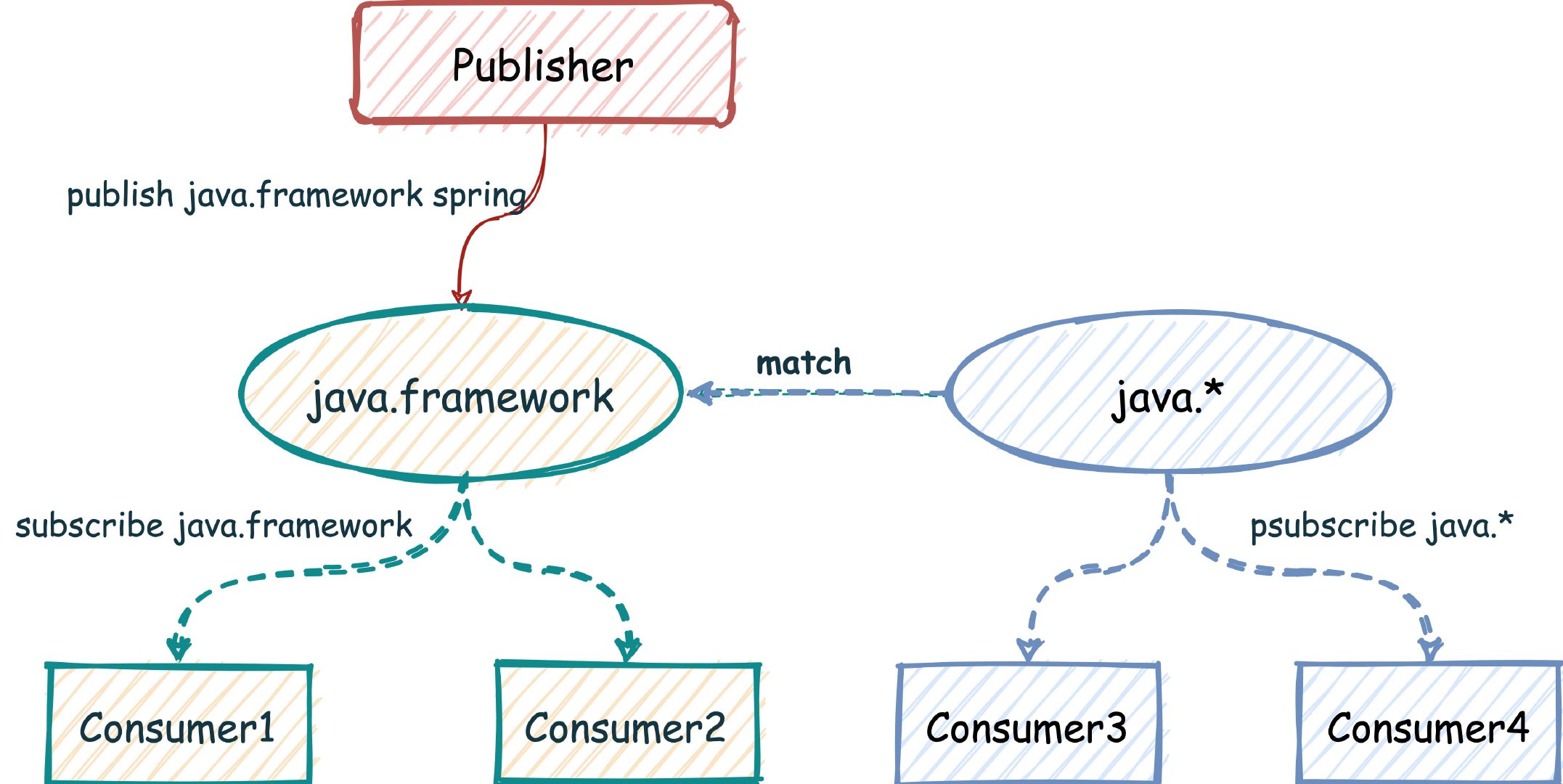
先启动两个客户端订阅(subscribe) 名字叫 framework 的频道,然后第三个客户端往 framework 发消息,可以看到前两个客户端都会接收到对应的消息:
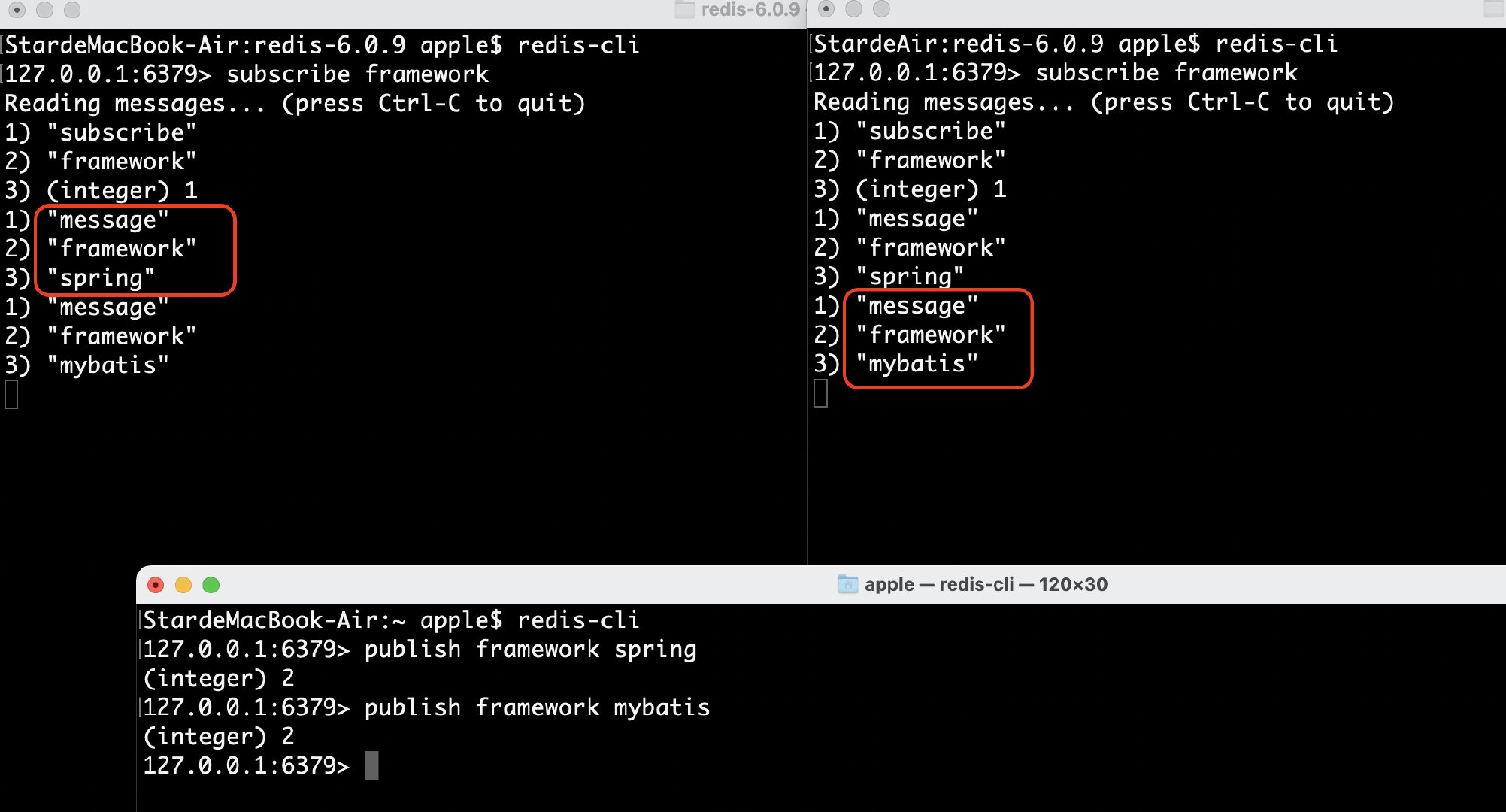
我们可以看到订阅的客户端每次可以收到一个 3 个参数的消息,分别为:
- 消息的种类
- 始发频道的名称
- 实际的消息
再来看下订阅符合给定模式的频道,这回订阅的命令是 PSUBSCRIBE

我们往 java.framework 这个频道发送了一条消息,不止订阅了该频道的 Consumer1 和 Consumer2 可以接收到消息,订阅了模式 java.* 的 Consumer3 和 Consumer4 也可以接收到消息。
Pub/Sub 常用命令:
| 命令 | 用法 | 描述 |
|---|---|---|
| PSUBSCRIBE | PSUBSCRIBE pattern [pattern …] | 订阅一个或多个符合给定模式的频道 |
| PUBSUB | PUBSUB subcommand [argument [argument …]] | 查看订阅与发布系统状态 |
| PUBLISH | PUBLISH channel message | 将信息发送到指定的频道 |
| PUNSUBSCRIBE | PUNSUBSCRIBE [pattern [pattern …]] | 退订所有给定模式的频道 |
| SUBSCRIBE | SUBSCRIBE channel [channel …] | 订阅给定的一个或多个频道的信息 |
| UNSUBSCRIBE | UNSUBSCRIBE [channel [channel …]] | 指退订给定的频道 |
2.3 Streams 实现消息队列
Redis 发布订阅 (pub/sub) 有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。而且也没有 Ack 机制来保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。
后来 Redis 的父亲 Antirez,又单独开启了一个叫 Disque 的项目来完善这些问题,但是没有做起来,github 的更新也定格在了 5 年前,所以我们就不讨论了。
Redis 5.0 版本新增了一个更强大的数据结构——Stream。它提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
它就像是个仅追加内容的消息链表,把所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。而且消息是持久化的。
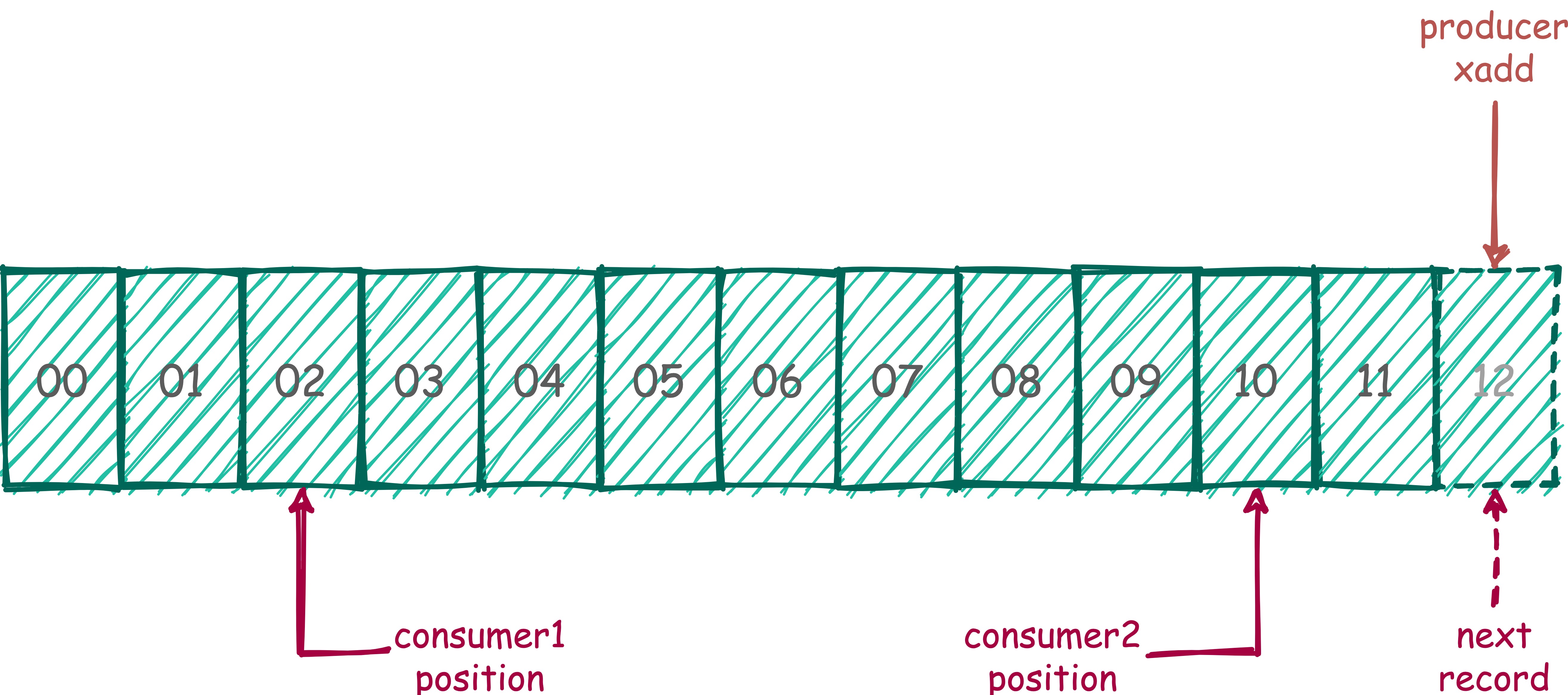
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
Streams 是 Redis 专门为消息队列设计的数据类型,所以提供了丰富的消息队列操作命令。
Stream 常用命令
| 命令 | 描述 | 用法 |
|---|---|---|
| XADD | 添加消息到末尾,保证有序,可以自动生成唯一ID | XADD key ID field value [field value …] |
| XTRIM | 对流进行修剪,限制长度 | XTRIM key MAXLEN [~] count |
| XDEL | 删除消息 | XDEL key ID [ID …] |
| XLEN | 获取流包含的元素数量,即消息长度 | XLEN key |
| XRANGE | 获取消息列表,会自动过滤已经删除的消息 | XRANGE key start end [COUNT count] |
| XREVRANGE | 反向获取消息列表,ID 从大到小 | XREVRANGE key end start [COUNT count] |
| XREAD | 以阻塞或非阻塞方式获取消息列表 | XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] id [id …] |
| XGROUP CREATE | 创建消费者组 | XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] |
| XREADGROUP GROUP | 读取消费者组中的消息 | XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key …] ID [ID …] |
| XACK | 将消息标记为”已处理” | XACK key group ID [ID …] |
| XGROUP SETID | 为消费者组设置新的最后递送消息ID | XGROUP SETID [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] |
| XGROUP DELCONSUMER | 删除消费者 | XGROUP DELCONSUMER [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] |
| XGROUP DESTROY | 删除消费者组 | XGROUP DESTROY [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DEL |
| XPENDING | 显示待处理消息的相关信息 | XPENDING key group [start end count] [consumer] |
| XCLAIM | 转移消息的归属权 | XCLAIM key group consumer min-idle-time ID [ID …] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] |
| XINFO | 查看流和消费者组的相关信息 | XINFO [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
| XINFO GROUPS | 打印消费者组的信息 | XINFO GROUPS [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
| XINFO STREAM | 打印流信息 | XINFO STREAM [CONSUMERS key groupname] [GROUPS key] [STREAM key] [HELP] |
CRUD 工程师上线
增删改查来一波
# * 号表示服务器自动生成 ID,后面顺序跟着一堆 key/value
127.0.0.1:6379> xadd mystream * f1 v1 f2 v2 f3 v3
"1609404470049-0" ## 生成的消息 ID,有两部分组成,毫秒时间戳-该毫秒内产生的第1条消息
# 消息ID 必须要比上个 ID 大
127.0.0.1:6379> xadd mystream 123 f4 v4
(error) ERR The ID specified in XADD is equal or smaller than the target stream top item
# 自定义ID
127.0.0.1:6379> xadd mystream 1609404470049-1 f4 v4
"1609404470049-1"
# -表示最小值 , + 表示最大值,也可以指定最大消息ID,或最小消息ID,配合 -、+ 使用
127.0.0.1:6379> xrange mystream - +
1) 1) "1609404470049-0"
2) 1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "f3"
6) "v3"
2) 1) "1609404470049-1"
2) 1) "f4"
2) "v4"
127.0.0.1:6379> xdel mystream 1609404470049-1
(integer) 1
127.0.0.1:6379> xlen mystream
(integer) 1
# 删除整个 stream
127.0.0.1:6379> del mystream
(integer) 1
独立消费
xread 以阻塞或非阻塞方式获取消息列表,指定 BLOCK 选项即表示阻塞,超时时间 0 毫秒(意味着永不超时)
# 从ID是0-0的开始读前2条
127.0.0.1:6379> xread count 2 streams mystream 0
1) 1) "mystream"
2) 1) 1) "1609405178536-0"
2) 1) "f5"
2) "v5"
2) 1) "1609405198676-0"
2) 1) "f1"
2) "v1"
3) "f2"
4) "v2"
# 阻塞的从尾部读取流,开启新的客户端xadd后发现这里就读到了,block 0 表示永久阻塞
127.0.0.1:6379> xread block 0 streams mystream $
1) 1) "mystream"
2) 1) 1) "1609408791503-0"
2) 1) "f6"
2) "v6"
(42.37s)
可以看到,我并没有给流 mystream 传入一个常规的 ID,而是传入了一个特殊的 ID $这个特殊的 ID 意思是 XREAD 应该使用流 mystream 已经存储的最大 ID 作为最后一个 ID。以便我们仅接收从我们开始监听时间以后的新消息。这在某种程度上相似于 Unix 命令tail -f。
当然,也可以指定任意有效的 ID。
而且, XREAD 的阻塞形式还可以同时监听多个 Strema,只需要指定多个键名即可。
127.0.0.1:6379> xread block 0 streams mystream yourstream $ $
创建消费者组
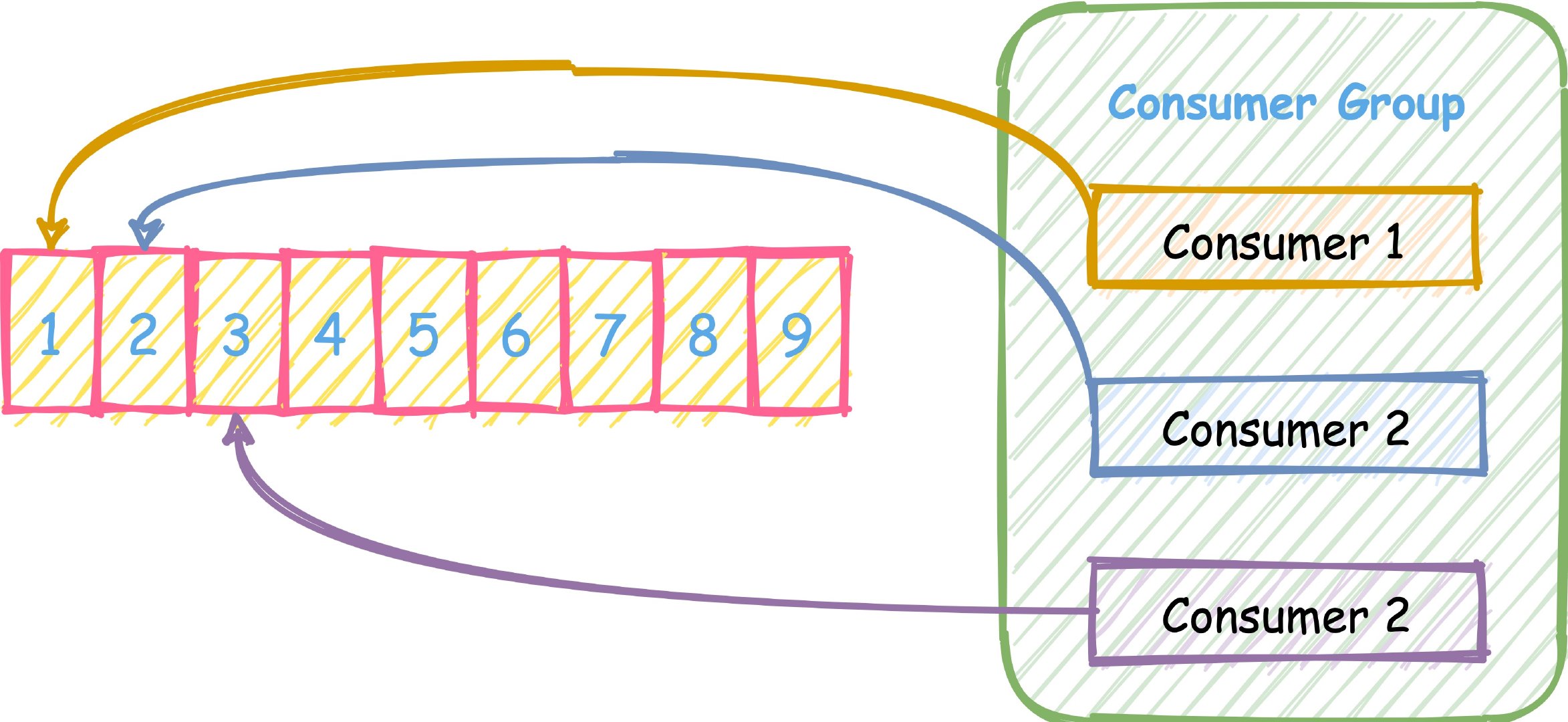
xread 虽然可以扇形分发到 N 个客户端,然而,在某些问题中,我们想要做的不是向许多客户端提供相同的消息流,而是从同一流向许多客户端提供不同的消息子集。比如下图这样,三个消费者按轮训的方式去消费一个 Stream。
Redis Stream 借鉴了很多 Kafka 的设计。
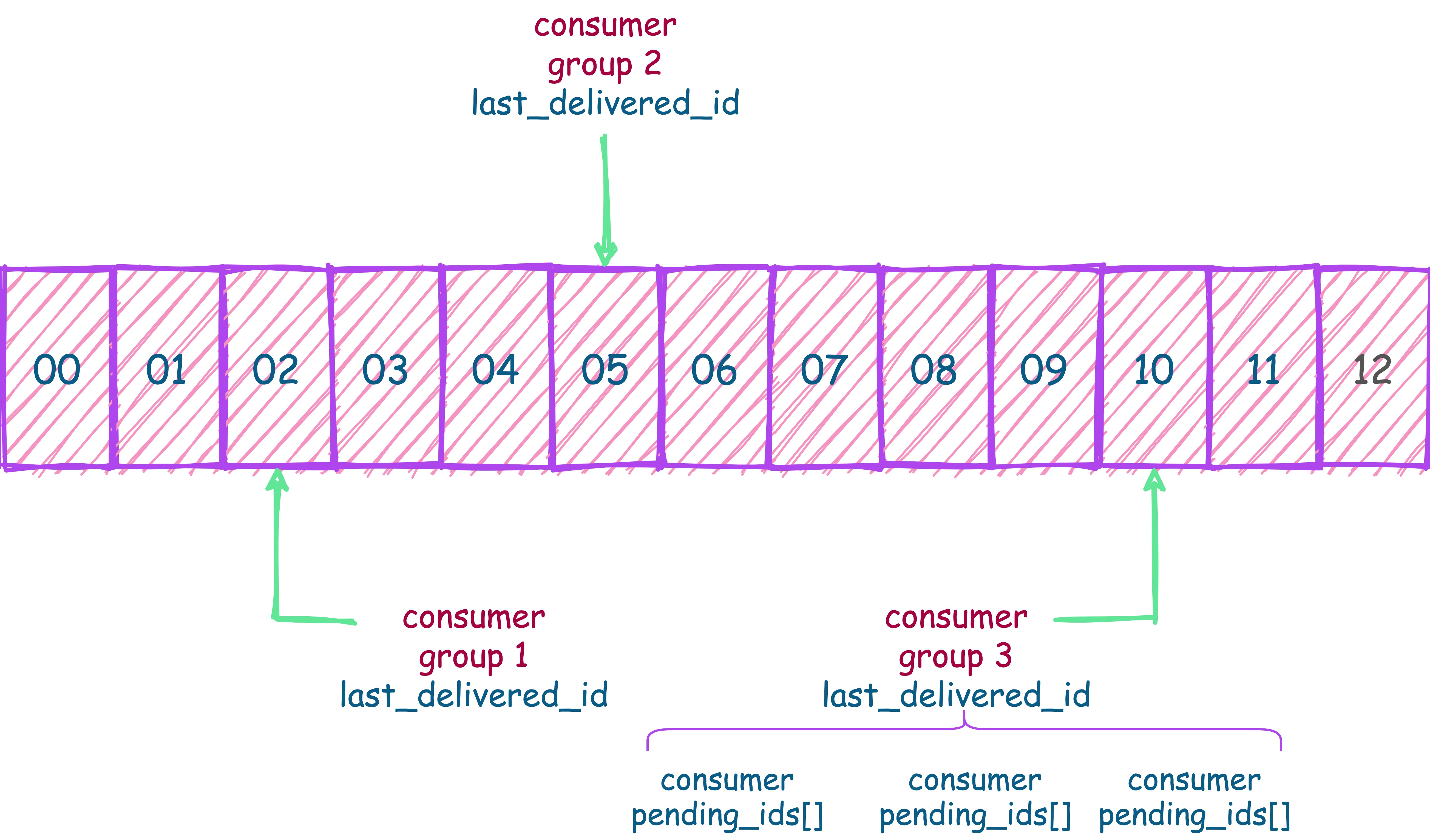
Consumer Group:有了消费组的概念,每个消费组状态独立,互不影响,一个消费组可以有多个消费者
last_delivered_id :每个消费组会有个游标 last_delivered_id 在数组之上往前移动,表示当前消费组已经消费到哪条消息了
pending_ids :消费者的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为
PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
Stream 不像 Kafak 那样有分区的概念,如果想实现类似分区的功能,就要在客户端使用一定的策略将消息写到不同的 Stream。
xgroup create:创建消费者组xgreadgroup:读取消费组中的消息xack:ack 掉指定消息
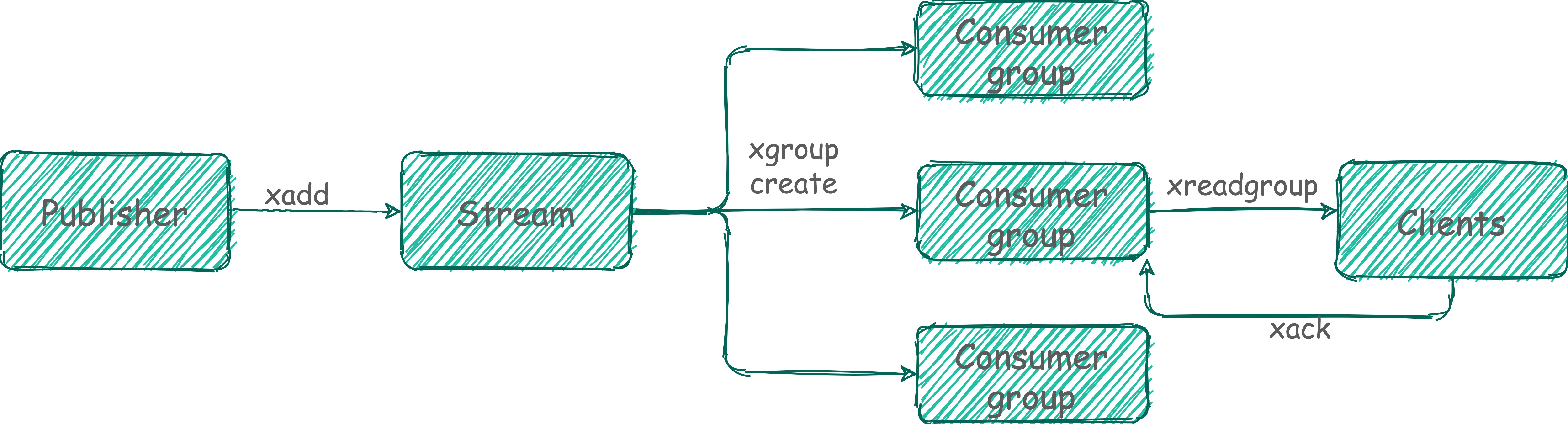
# 创建消费者组的时候必须指定 ID, ID 为 0 表示从头开始消费,为 $ 表示只消费新的消息,也可以自己指定
127.0.0.1:6379> xgroup create mystream mygroup $
OK
# 查看流和消费者组的相关信息,可以查看流、也可以单独查看流下的某个组的信息
127.0.0.1:6379> xinfo stream mystream
1) "length"
2) (integer) 4 # 共 4 个消息
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1609408943089-0"
9) "groups"
10) (integer) 1 # 一个消费组
11) "first-entry" # 第一个消息
12) 1) "1609405178536-0"
2) 1) "f5"
2) "v5"
13) "last-entry" # 最后一个消息
14) 1) "1609408943089-0"
2) 1) "f6"
2) "v6"
127.0.0.1:6379>
按消费组消费
Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息 ID。它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的 PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除。
# 消费组 mygroup1 中的 消费者 c1 从 mystream 中 消费组数据
# > 号表示从当前消费组的 last_delivered_id 后面开始读
# 每当消费者读取一条消息,last_delivered_id 变量就会前进
127.0.0.1:6379> xreadgroup group mygroup1 c1 count 1 streams mystream >
1) 1) "mystream"
2) 1) 1) "1609727806627-0"
2) 1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "f3"
6) "v3"
127.0.0.1:6379> xreadgroup group mygroup1 c1 count 1 streams mystream >
1) 1) "mystream"
2) 1) 1) "1609727818650-0"
2) 1) "f4"
2) "v4"
# 已经没有消息可读了
127.0.0.1:6379> xreadgroup group mygroup1 c1 count 2 streams mystream >
(nil)
# 还可以阻塞式的消费
127.0.0.1:6379> xreadgroup group mygroup1 c2 block 0 streams mystream >
µ1) 1) "mystream"
2) 1) 1) "1609728270632-0"
2) 1) "f5"
2) "v5"
(89.36s)
# 观察消费组信息
127.0.0.1:6379> xinfo groups mystream
1) 1) "name"
2) "mygroup1"
3) "consumers"
4) (integer) 2 # 2个消费者
5) "pending"
6) (integer) 3 # 共 3 条正在处理的信息还没有 ack
7) "last-delivered-id"
8) "1609728270632-0"
127.0.0.1:6379> xack mystream mygroup1 1609727806627-0 # ack掉指定消息
(integer) 1
尝鲜到此结束,就不继续深入了。
个人感觉,就目前来说,Stream 还是不能当做主流的 MQ 来使用的,而且使用案例也比较少,慎用。
写在最后
当然,还有需要注意的就是,业务上避免过度复用一个 Redis。既用它做缓存、做计算,还拿它做任务队列,这样的话 Redis 会很累的。
没有绝对好的技术、只有对业务最友好的技术,共勉
以梦为马,越骑越傻。诗和远方,越走越慌。不忘初心是对的,但切记要出发,加油吧,程序员。
