
我们总说的 Redis 具有高可靠性,其实,这里有两层含义:一是数据尽量少丢失,二是服务尽量少中断。
AOF 和 RDB 保证了前者,而对于后者,Redis 的做法就是增加副本冗余量,将一份数据同时保存在多个实例上,来避免单点故障。即使有一个实例出现了故障,需要过一段时间才能恢复,其他实例也可以对外提供服务,不会影响业务使用。
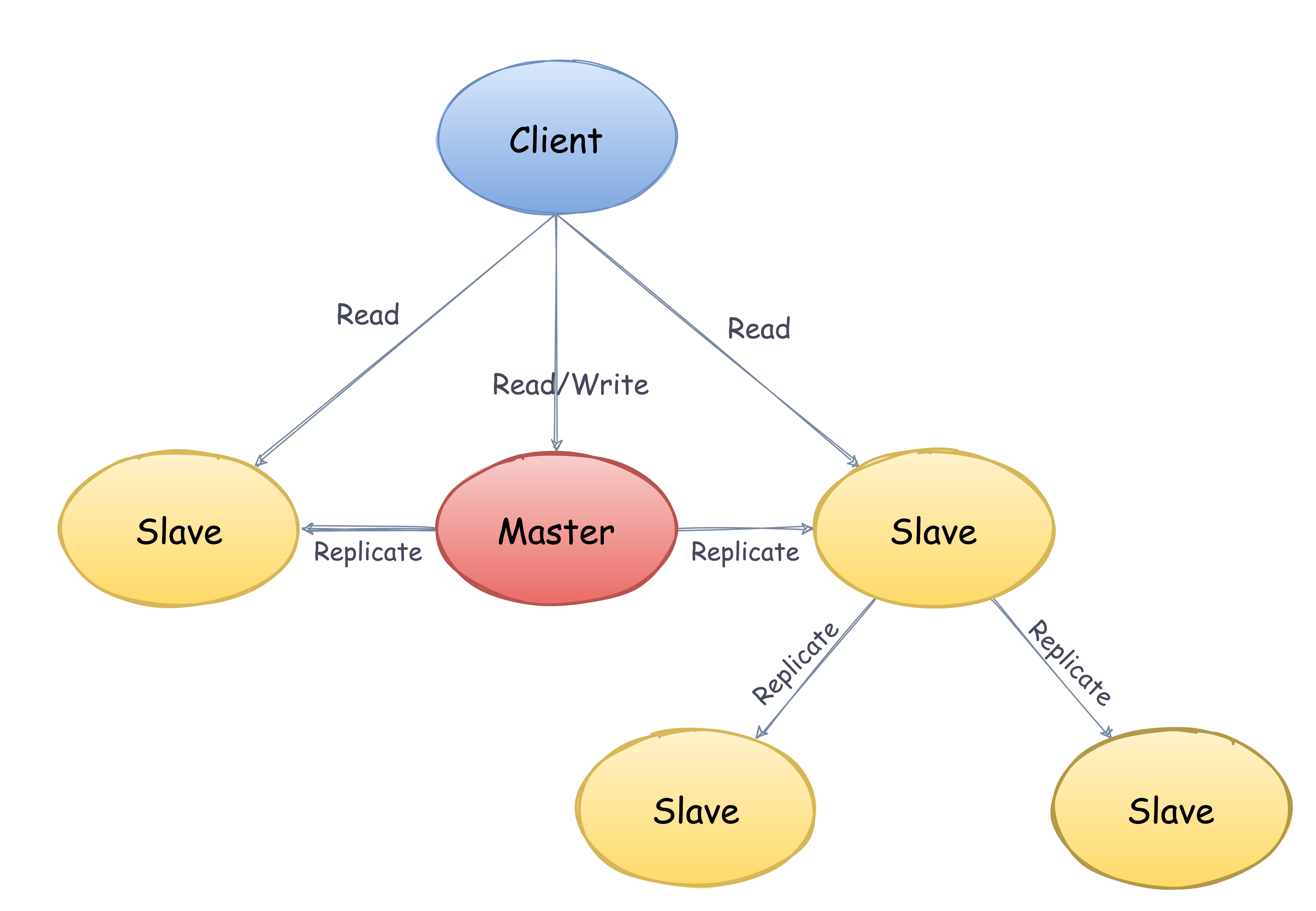
这就是 Redis 的主从模式,主从库之间采用的是读写分离的方式。
一、主从复制是啥
主从复制,或者叫 主从同步,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 **主节点(master)**,后者称为 **从节点(slave)**。且数据的复制是 单向 的,只能由主节点到从节点。
Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
二、主从复制的目的
- 数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 *(实际上是一种服务的冗余)*。
- 负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础,因此说主从复制是 Redis 高可用的基础。
三、Hello world
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof,当然目前该命名也是向后兼容的,高版本也可以使用)命令形成主库和从库的关系
以下三种方式是 完全等效 的:
- 配置文件:在从服务器的配置文件中加入:
replicaof <masterip> <masterport> - 启动命令:redis-server 启动命令后加入
--replicaof <masterip> <masterport> - 客户端命令:Redis 服务器启动后,直接通过客户端执行命令:
replicaof <masterip> <masterport>,让该 Redis 实例成为从节点。
需要注意的是:主从复制的开启,完全是在从节点发起的,不需要我们在主节点做任何事情。即: 配从(库)不配主(库)
3.1 本地启动两个节点
在正确安装好 Redis 之后,我们可以使用 redis-server --port 的方式指定创建两个不同端口的 Redis 实例,例如,下方我分别创建了一个 6379 和 6380 的两个 Redis 实例:
# 创建一个端口为 6379 的 Redis 实例
redis-server --port 6379
# 创建一个端口为 6380 的 Redis 实例
redis-server --port 6380
此时两个 Redis 节点启动后,都默认为 主节点。
3.2 建立复制
我们在 6380 端口的节点中执行 replicaof 命令,使之变为从节点:
# 在 6380 端口的 Redis 实例中使用控制台
redis-cli -p 6380
# 成为本地 6379 端口实例的从节点
127.0.0.1:6380> REPLICAOF 127.0.0.1 6379
OK
3.3 观察效果
下面我们来验证一下,主节点的数据是否会复制到从节点之中:
先在 从节点 中查询一个 不存在 的 key:
127.0.0.1:6380> GET k1
(nil)
再在 主节点 中添加这个 key
127.0.0.1:6379> SET k1 v1
OK
此时再从 从节点 中查询,会发现已经从 主节点 同步到 从节点:
127.0.0.1:6380> GET k1
“v1”
3.4 查看信息
可以通过 info replication 查看当前节点的复制信息
127.0.0.1:6380> REPLICAOF 127.0.0.1 6379
OK
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_repl_offset:654
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:be40ad10c509c150291dc571035dcb2eef835a38
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:654
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:655
repl_backlog_histlen:0
3.5 断开复制
通过 REPLICAOF host port 命令建立主从复制关系以后,可以通过 replicaof no one 断开。需要注意的是,从节点断开复制后,不会删除已有的数据,只是不再接受主节点新的数据变化。
127.0.0.1:6380> replicaof no one
OK
四、主从复制的工作过程
带着这几个疑问继续
- 主从库同步是如何完成的呢?
- 主库数据是一次性传给从库,还是分批同步?
- 如果主从库间的网络断连了,数据还能保持一致吗?
Redis 主从库之间的同步,在不同阶段有不同的处理方式,我们先来看下主从库通过 replicaof 建立连接之后,第一次同步是怎么进行的
4.1 全量复制 | 快照同步
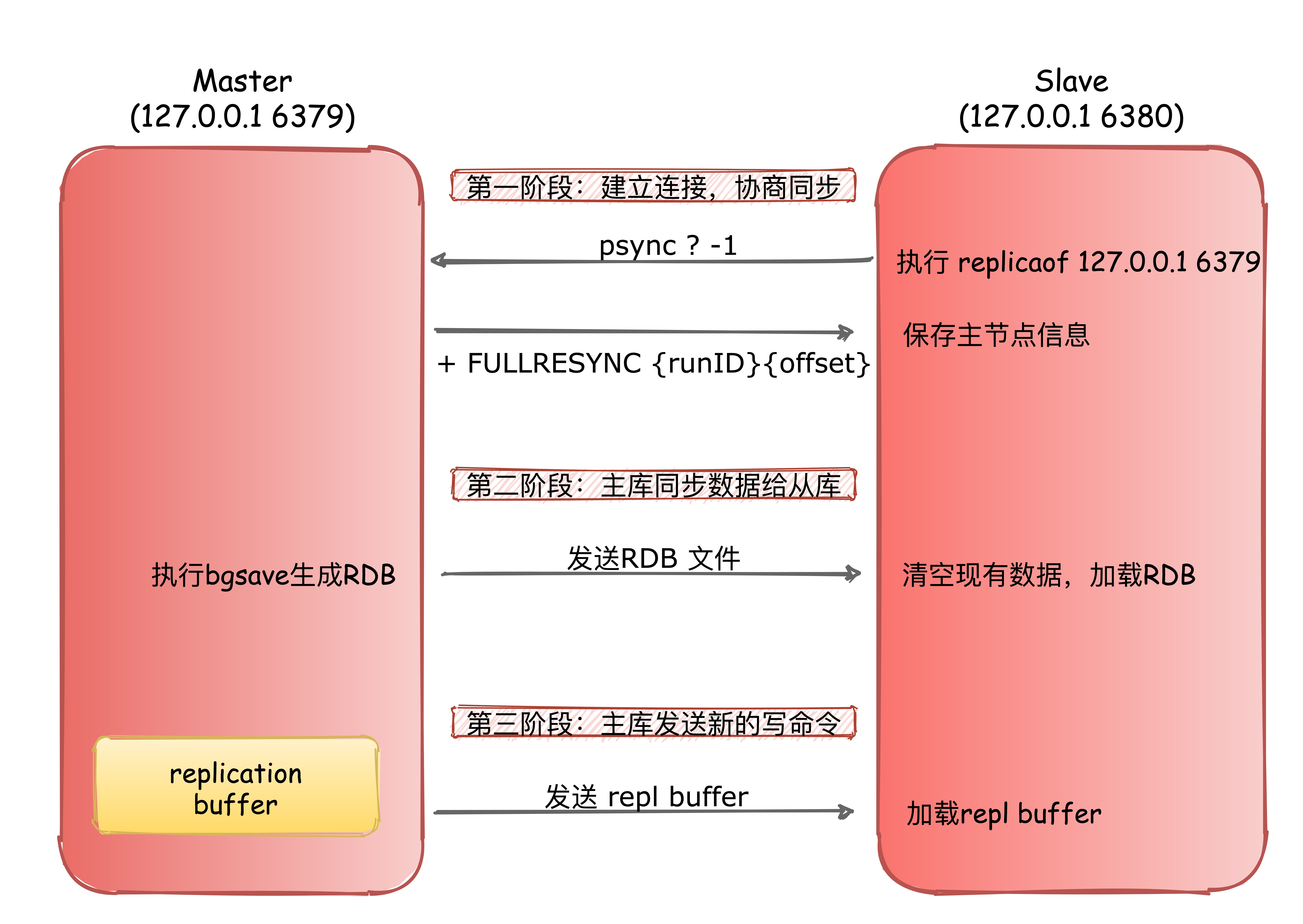
为了节省篇幅,我把主要的步骤都 浓缩 在了上图中,其实也可以 简化成三个阶段:建立连接阶段-数据同步阶段-命令传播阶段。
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。(2.8 版本之前的
SYNC不做介绍)- runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“ ?”。
- offset,此时设为 -1,表示第一次复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。
这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
这一步其实还有很多其他的流程,比如从节点会发送 ping 检查 socket 连接是否可用。如果 master 设置了 requirepass ,那 slave 节点就必须设置 masterauth 选项来进行身份验证…
第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。
在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的
replication buffer,记录 RDB 文件生成后收到的所有写操作。最后,也就是第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。
具体的操作是,当主库完成 RDB 文件发送后,就会把此时
replication buffer中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
主库压力问题 | 主从级联模式
从主从库之间的第一次数据同步过程,可以看到,一次全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量同步。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。
所以 Redis 也支持 “ 主 - 从 - 从” 这样的模式。
其实就是通过级联的方式,将主库的压力分担给部分从库。
我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
replicaof 所选从库的IP 6379
再看下文章开头的图。
无盘复制
主节点在进行快照同步时,会进行很重的文件 IO 操作,特别是对于非 SSD 磁盘存储时,快照会对系统的负载产生较大影响。特别是当系统正在进行 AOF 的 fsync 操作时如果发生快照,fsync 将会被推迟执行,这就会严重影响主节点的服务效率。
所以从 Redis 2.8.18 版开始支持无盘复制。所谓无盘复制是指主服务器直接通过套接字 socket 将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存,一边将序列化的内容发送到从节点,从节点还是跟之前一样,先将接收到的内容存储到磁盘文件中,再进行一次性加载。
4.2 命令传播
一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为 基于长连接的命令传播,可以避免频繁建立连接的开销。
心跳机制
在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING 和 REPLCONF ACK。心跳机制对于主从复制的超时判断、数据安全等有作用。
每隔指定的时间,从节点会向主节点发送 PING 命令, 并报告复制流的处理情况。
PING 发送的频率由
repl-ping-slave-period参数控制,单位是秒,默认值是 10s。在命令传播阶段,从节点会向主节点发送 REPLCONF ACK 命令,频率是每秒 1 次;命令格式为:
REPLCONF ACK {offset},其中 offset 指从节点保存的复制偏移量。REPLCONF ACK 命令的作用包括:- 实时监测主从节点网络状态:该命令会被主节点用于复制超时的判断。此外,在主节点中使用 info Replication,可以看到其从节点的状态中的 lag 值,代表的是主节点上次收到该 REPLCONF ACK 命令的时间间隔,在正常情况下,该值应该是 0 或 1
- 检测命令丢失:从节点发送了自身的 offset,主节点会与自己的 offset 对比,如果从节点数据缺失(如网络丢包),主节点会推送缺失的数据(这里也会利用复制积压缓冲区)。注意,offset 和复制积压缓冲区,不仅可以用于部分复制,也可以用于处理命令丢失等情形;区别在于前者是在断线重连后进行的,而后者是在主从节点没有断线的情况下进行的。
- 辅助保证从节点的数量和延迟:Redis 主节点中使用
min-slaves-to-write和min-slaves-max-lag参数,来保证主节点在不安全的情况下不会执行写命令;所谓不安全,是指从节点数量太少,或延迟过高。例如min-slaves-to-write和min-slaves-max-lag分别是 3 和 10,含义是如果从节点数量小于 3 个,或所有从节点的延迟值都大于 10s,则主节点拒绝执行写命令。而这里从节点延迟值的获取,就是通过主节点接收到 REPLCONF ACK 命令的时间来判断的,即前面所说的 info Replication 中的 lag 值。
不过, 因为 Redis 主从使用异步复制, 这就意味着当主节点挂掉时,从节点可能没有收到全部的同步消息,这部分未同步的消息就丢失了。如果主从延迟特别大,那么丢失的数据就可能会特别多。
4.3 增量复制 | 部分复制
你以为这样主从同步就结束了?
万一网络断连或者网络阻塞,主从库之间的长连接就断了,接下来就面临一个继续同步的问题。
在 Redis 2.8 之前,如果主从库在命令传播时出现了网络闪断,那么,从库就会和主库重新进行一次全量复制,开销非常大。
从 Redis 2.8 开始,网络断了之后,主从库会采用 增量复制 的方式继续同步。
增量复制的原理主要是靠主从节点分别维护一个 复制偏移量,有了这个偏移量,断线重连之后一比较,之后就可以仅仅把从服务器断线之后缺失的这部分数据给补回来了。
全量复制中有 replication buffer 这样的缓存区来保存 RDB 文件生成后收到的所有写操作,增量复制中也有一个缓存区,叫 repl_backlog_buffer ,默认是 1M。
当主从库断连后,主库会把断连期间收到的写操作命令,写入
replication buffer,同时也会把这些操作命令也写入repl_backlog_buffer这个缓冲区。
repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
主库对应的偏移量是 master_repl_offset,从库的偏移量 slave_repl_offset 。正常情况下,这两个偏移量基本相等。
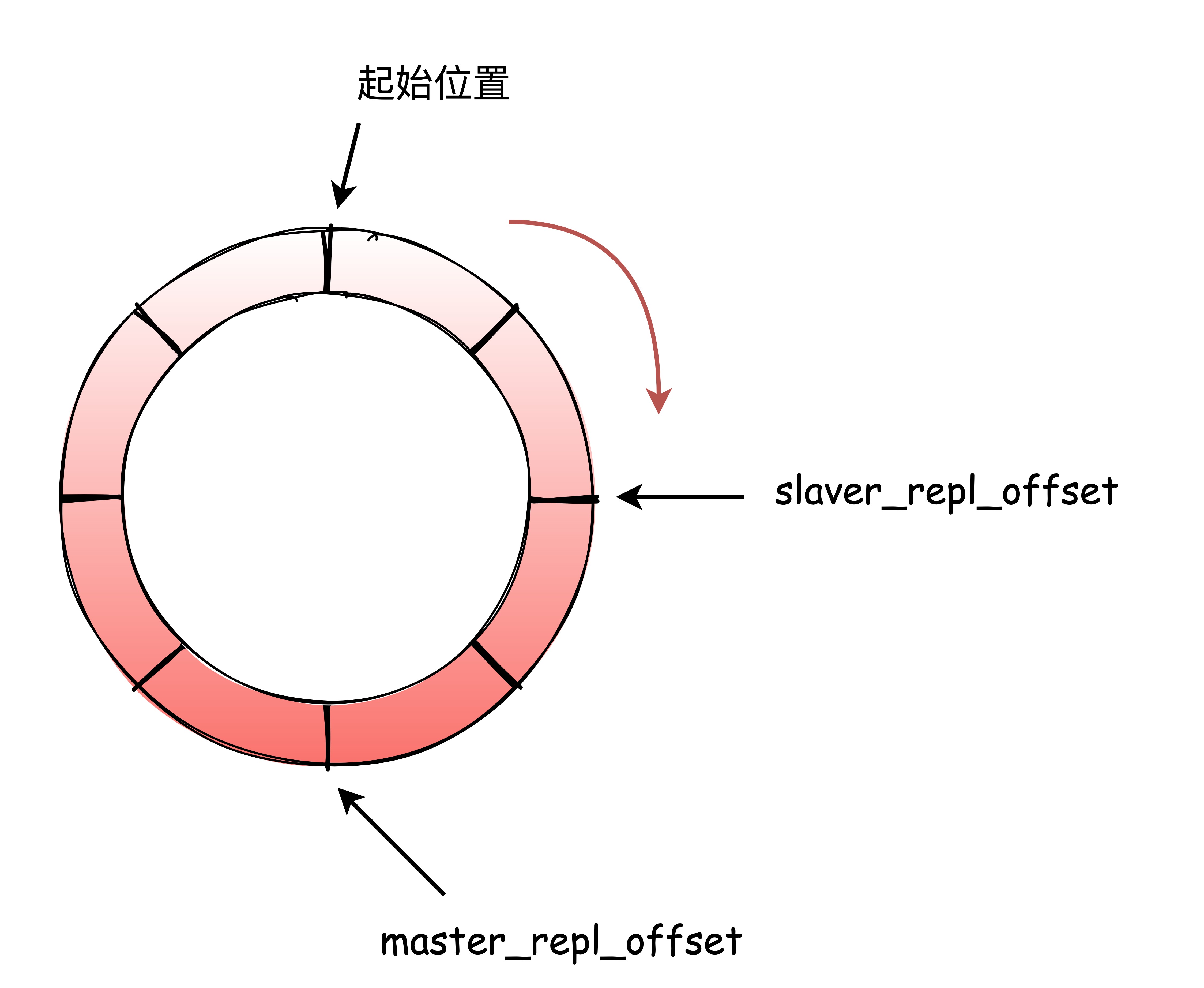
在网络断连阶段,主库可能会收到新的写操作命令,这时,master_repl_offset 会大于 slave_repl_offset。此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就可以了。
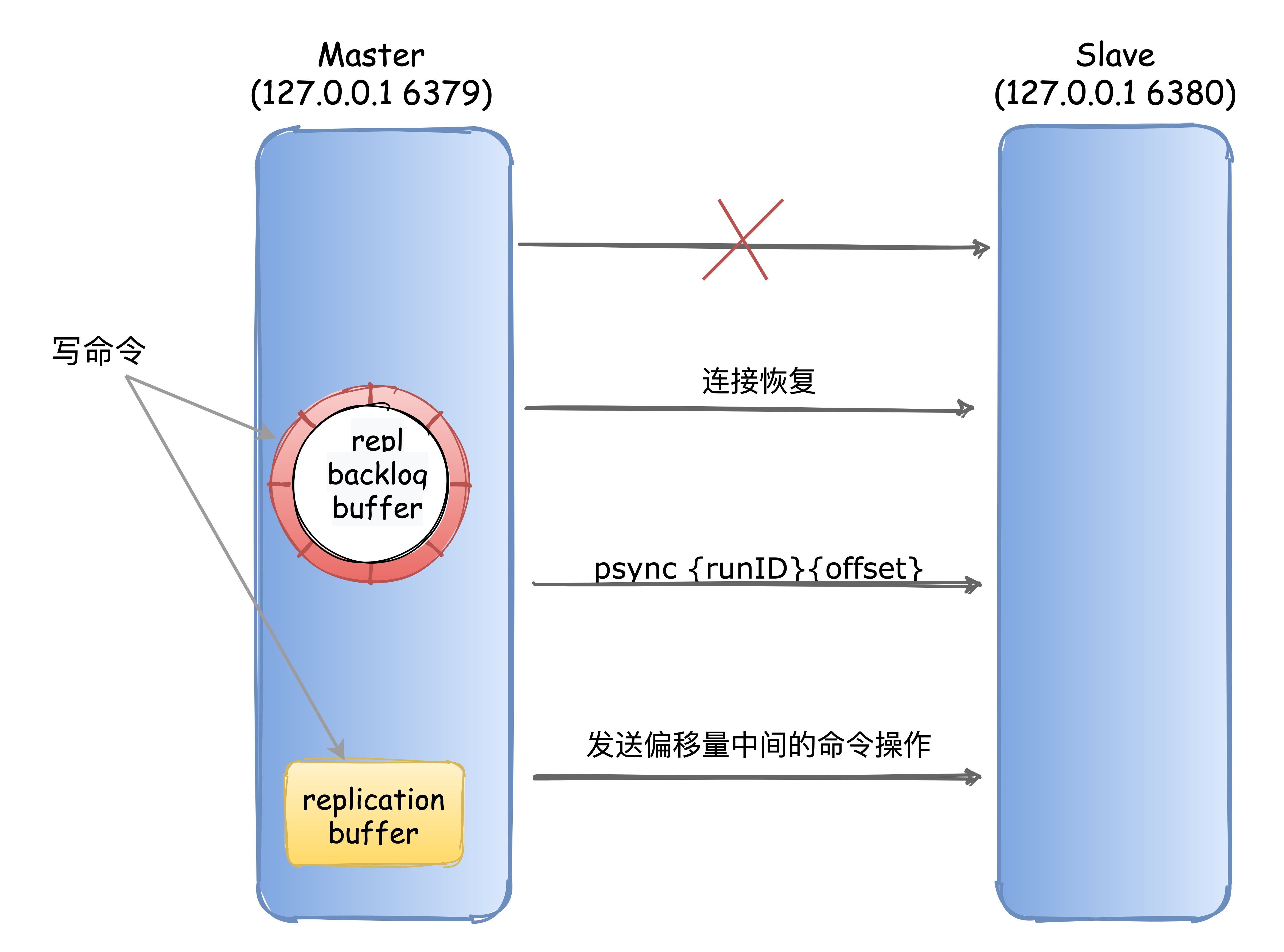
PS:因为 repl_backlog_buffer 是一个环形缓冲区(可以理解为是一个定长的环形数组),所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。如果从库和主库断连时间过长,造成它在主库 repl_backlog_buffer 的 slave_repl_offset 位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。
因此,我们要想办法避免这一情况,一般而言,我们可以调整 repl_backlog_size 这个参数。这个参数和所需的缓冲空间大小有关。缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl_backlog_size = 缓冲空间大小 * 2,这也就是 repl_backlog_size 的最终值。
举个例子,如果主库每秒写入 2000 个操作,每个操作的大小为 2KB,网络每秒能传输 1000 个操作,那么,有 1000 个操作需要缓冲起来,这就至少需要 2MB 的缓冲空间。否则,新写的命令就会覆盖掉旧操作了。为了应对可能的突发压力,我们最终把 repl_backlog_size 设为 4MB。
这样一来,增量复制时主从库的数据不一致风险就降低了。不过,如果并发请求量非常大,连两倍的缓冲空间都存不下新操作请求的话,此时,主从库数据仍然可能不一致。
五、小结
Redis 的主从库同步的基本原理,总结来说,有三种模式:全量复制、基于长连接的命令传播,以及增量复制。
全量复制虽然耗时,但是对于从库来说,如果是第一次同步,全量复制是无法避免的,所以,一个 Redis 实例的数据库不要太大,一个实例大小在几 GB 级别比较合适,这样可以减少 RDB 文件生成、传输和重新加载的开销。另外,为了避免多个从库同时和主库进行全量复制,给主库过大的同步压力,我们也可以采用“主 - 从 - 从”这一级联模式,来缓解主库的压力。
我们常用一主二仆的配置,即一个主节点对应两个从节点。
主从复制是 Redis 分布式的基础,Redis 的高可用离开了主从复制将无从进行。
参考
- https://www.cnblogs.com/kismetv/p/9236731.html
- 《Redis 核心技术与实战》