
我们知道 Reids 提供了主从模式的机制,来保证可用性,可是如果主库发生故障了,那就直接会影响到从库的同步,怎么办呢?
所以,如果主库挂了,我们就需要运行一个新主库,比如说把一个从库切换为主库,把它当成主库。这就涉及到三个问题:
- 主库真的挂了吗?
- 该选择哪个从库作为主库?
- 怎么把新主库的相关信息通知给从库和客户端呢?
围绕这 3 个问题,我们来看下不需要人工干预就可以解决这三个问题的 Redis 哨兵。
一、Redis Sentinel 哨兵
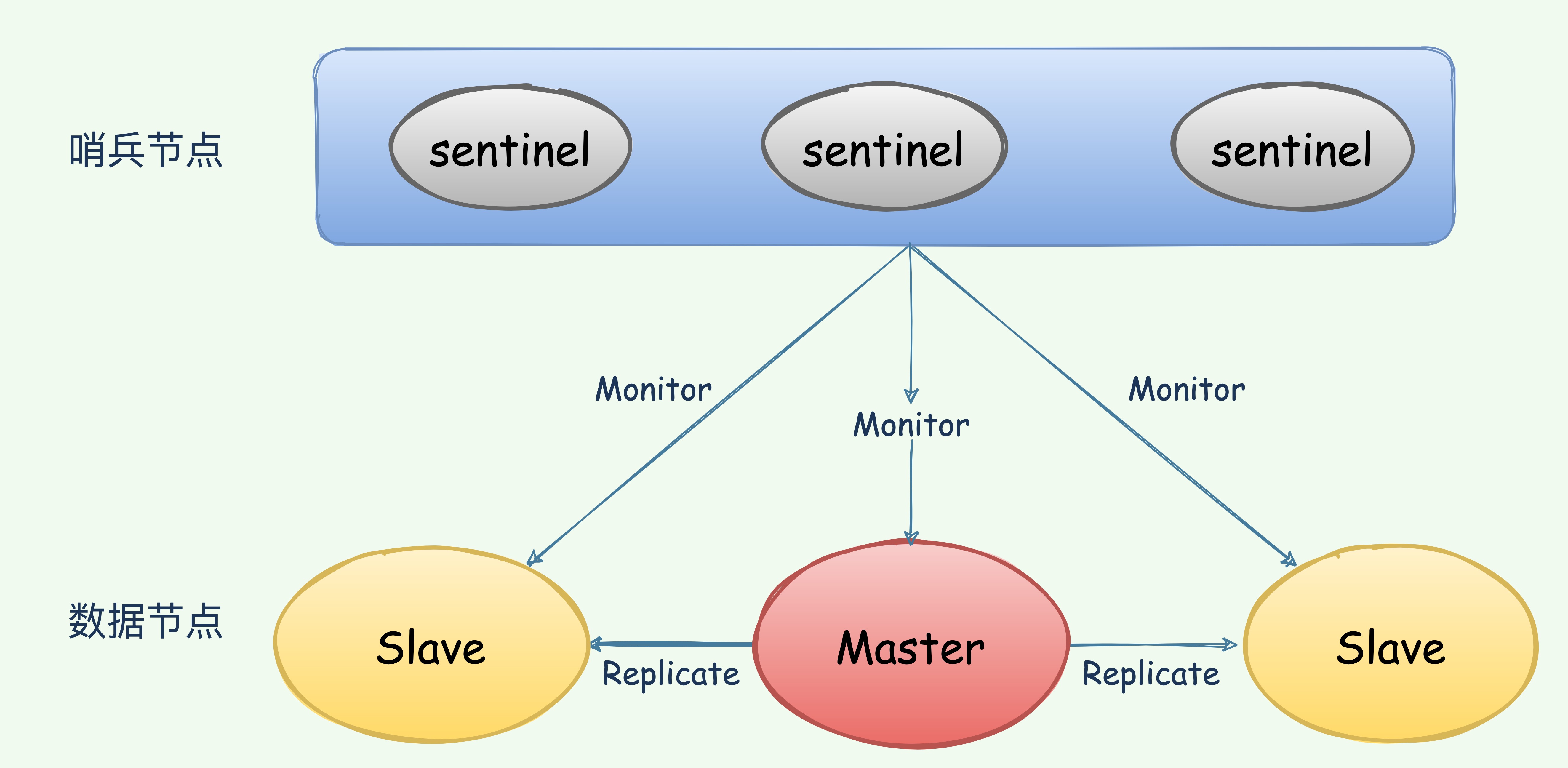
上图 展示了一个典型的哨兵架构图,它由两部分组成,哨兵节点和数据节点:
- 哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据;
- 数据节点: 主节点和从节点都是数据节点;
在复制的基础上,哨兵实现了 自动化的故障恢复 功能,下面是官方对于哨兵功能的描述:
监控(Monitoring): 哨兵会不断地检查主节点和从节点是否运作正常。
监控是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。如果从库没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为“下线状态”;同样,如果主库也没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主库下线,然后开始自动切换主库的流程。
通知(Notification): 当被监控的某个 Redis 服务器出现问题时, 哨兵可以通过 API 向管理员或者其他应用程序发送通知。
在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行
replicaof命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。自动故障转移(Automatic failover)/ 选主: 当 主节点 不能正常工作时,哨兵会开始 自动故障转移操作,它会将失效主节点的其中一个 从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
配置提供者(Configuration provider): 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点故障并完成转移。而配置提供者和通知功能,则需要在与客户端的交互中才能体现。
二、 Hello Wolrd
2.1 部署主从节点
哨兵系统中的主从节点,与普通的主从节点配置是一样的,并不需要做任何额外配置。
下面分别是主节点(port=6379)和 2 个从节点(port=6380、6381)的配置文件:
#redis.conf master
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
#redis_6380.conf
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
replicaof 127.0.0.1 6379
#redis_6381.conf
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
replicaof 127.0.0.1 6379
然后我们可以执行 redis-server 来根据配置文件启动不同的 Redis 实例,依次启动主从节点:
redis-server redis.conf
redis-server redis_6380.conf
redis-server redis_6381.conf
节点启动后,我们执行 redis-cli 默认连接到我们端口为 6379 的主节点执行 info Replication 检查一下主从状态是否正常:(可以看到下方正确地显示了两个从节点)
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=154,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=140,lag=1
master_replid:52a58d69125881d3af366d0559439377a70ae879
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:154
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:154
2.2 部署哨兵节点
按照上面同样的方法,我们给哨兵节点也创建三个配置文件。*(哨兵节点本质上是特殊的 Redis 节点,所以配置几乎没什么差别,只是在端口上做区分就好,每个哨兵只需要配置监控主节点,就可以自动发现其他的哨兵节点和从节点)*
# redis-sentinel-26379.conf
port 26379
daemonize yes
logfile "26379.log"
sentinel monitor mymaster 127.0.0.1 6379 2
# redis-sentinel-26380.conf
port 26380
daemonize yes
logfile "26380.log"
sentinel monitor mymaster 127.0.0.1 6379 2
# redis-sentinel-26381.conf
port 26381
daemonize yes
logfile "26381.log"
sentinel monitor mymaster 127.0.0.1 6379 2
其中,sentinel monitor mymaster 127.0.0.1 6379 2 配置的含义是:该哨兵节点监控 127.0.0.1:6379 这个主节点,该主节点的名称是 mymaster,最后的 2 的含义与主节点的故障判定有关:至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移。
启动 3 个哨兵节点:
redis-sentinel redis-sentinel-26379.conf
redis-sentinel redis-sentinel-26380.conf
redis-server redis-sentinel-26381.conf --sentinel #等同于 redis-sentinel redis-sentinel-26381.conf
使用 redis-cil 工具连接哨兵节点,并执行 info Sentinel 命令来查看是否已经在监视主节点了:
redis-cli -p 26380
127.0.0.1:26380> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
此时你打开刚才写好的哨兵配置文件,你还会发现出现了一些变化。
2.3 演示故障转移
我们先看下我们启动的 redis 进程,3 个数据节点,3 个哨兵节点
使用 kill 命令来杀掉主节点,同时 在哨兵节点中执行 info Sentinel 命令来观察故障节点的过程:
如果 刚杀掉瞬间 在哨兵节点中执行 info 命令来查看,会发现主节点还没有切换过来,因为哨兵发现主节点故障并转移需要一段时间:
# 第一时间查看哨兵节点发现并未转移,还在 6379 端口
127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
一段时间之后你再执行 info 命令,查看,你就会发现主节点已经切换成了 6381 端口的从节点:
# 过一段时间之后在执行,发现已经切换了 6381 端口
127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6381,slaves=2,sentinels=3
但同时还可以发现,哨兵节点认为新的主节点仍然有两个从节点 *(上方 slaves=2)*,这是因为哨兵在将 6381 切换成主节点的同时,将 6379 节点置为其从节点。虽然 6379 从节点已经挂掉,但是由于 哨兵并不会对从节点进行客观下线,因此认为该从节点一直存在。当 6379 节点重新启动后,会自动变成 6381 节点的从节点。
另外,在故障转移的阶段,哨兵和主从节点的配置文件都会被改写:
- 对于主从节点: 主要是
slaveof配置的变化,新的主节点没有了slaveof配置,其从节点则slaveof新的主节点。 - 对于哨兵节点: 除了主从节点信息的变化,纪元(epoch) (记录当前集群状态的参数) 也会变化,纪元相关的参数都 +1 了。
三、哨兵机制的工作流程
其实哨兵主要负责的就是三个任务:监控、选主和通知。
在监控和选主过程中,哨兵都需要做一些决策,比如
- 在监控任务中,哨兵需要判断主库、从库是否处于下线状态
- 在选主任务中,哨兵也要决定选择哪个从库实例作为主库
这就引出了两个概念,“主观下线”和“客观下线”
3.1 主观下线和客观下线
我先解释下什么是“主观下线”。
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态。如果哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为“主观下线”。
如果检测的是从库,那么,哨兵简单地把它标记为“主观下线”就行了,因为从库的下线影响一般不太大,集群的对外服务不会间断。
但是,如果检测的是主库,那么,哨兵还不能简单地把它标记为“主观下线”,开启主从切换。因为很有可能存在这么一个情况:那就是哨兵误判了,其实主库并没有故障。可是,一旦启动了主从切换,后续的选主和通知操作都会带来额外的计算和通信开销。
为了避免这些不必要的开销,我们要特别注意误判的情况。
误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。一旦哨兵判断主库下线了,就会开始选择新主库,并让从库和新主库进行数据同步,这个过程本身就会有开销,例如,哨兵要花时间选出新主库,从库也需要花时间和新主库同步。
那怎么减少误判呢?
在日常生活中,当我们要对一些重要的事情做判断的时候,经常会和家人或朋友一起商量一下,然后再做决定。
哨兵机制也是类似的,它通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
在判断主库是否下线时,不能由一个哨兵说了算,只有大多数的哨兵实例,都判断主库已经“主观下线”了,主库才会被标记为“客观下线”,这个叫法也是表明主库下线成为一个客观事实了。这个判断原则就是:少数服从多数。同时,这会进一步触发哨兵开始主从切换流程。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
3.2 选举领导者哨兵节点
当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。
监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是 Raft 算法;Raft 算法的基本思路是先到先得:即在一轮选举中,哨兵 A 向 B 发送成为领导者的申请,如果 B 没有同意过其他哨兵,则会同意 A 成为领导者。(Raft 算法:https://raft.github.io/)
3.3 故障转移
接着,选举出的领导者哨兵,开始故障转移操作,大概分 3 步:
- 第一步要做的就是在已下线主服务器属下的所有从服务器中,挑选出一个状态良好、数据完整的从服务器
- 第二步,更新主从状态,向选出的从服务器发送
slaveof no one命令,将这个从服务器转换为主服务器,并通过slaveof命令让其他节点成为其从节点 - 第三步将已下线的主节点设置为从节点
细说下第一步的选主过程
一般来说,我把哨兵选择新主库的过程称为“筛选 + 打分”。
筛选就是先过滤掉不健康的从节点,那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被 淘汰。
打分就是按 Redis 给定的三个规则,给剩下的从库逐个打分,将得分最高的从库选为新主库,这个规则分别是:
优先级最高的从库得分最高
用户可以通过
slave-priority配置项,给不同的从库设置不同优先级。比如,你有两个从库,它们的内存大小不一样,你可以手动给内存大的实例设置一个高优先级。在选主时,哨兵会给优先级高的从库打高分,如果有一个从库优先级最高,那么它就是新主库了。如果从库的优先级都一样,那么哨兵开始第二轮打分。和旧主库同步程度最接近的从库得分高
从库的
slave_repl_offset需要最接近master_repl_offset,即得分最高。ID 号小的从库得分高
每个实例都会有一个 runid,这个 ID 就类似于这里的从库的编号。目前,Redis 在选主库时,有一个默认的规定:在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库。
四、哨兵集群的原理
实际上,一旦多个实例组成了哨兵集群,即使有哨兵实例出现故障挂掉了,其他哨兵还能继续协作完成主从库切换的工作,包括判定主库是不是处于下线状态,选择新主库,以及通知从库和客户端。
认真看到这里的话,应该会有个疑问,我们在 hello world 环节中只是在哨兵节点加了一条配置
sentinel monitor mymaster 127.0.0.1 6379 2
怎么就能组成一个哨兵集群呢?
一套合理的监控机制是哨兵节点判定节点不可达的重要保证,Redis 哨兵通过三个定时监控任务完成对各个节点发现和监控:
每隔 10 秒,每个哨兵节点会向主节点和从节点发送 info 命令获取最新的拓扑结构
这个定时任务的作用具体可以表现在三个方面:
- 通过向主节点执行 info 命令,获取从节点的信息,这也是为什么哨兵节点不需要显式配置监控从节点。
- 当有新的从节点加入时都可以立刻感知出来。
- 节点不可达或者故障转移后,可以通过 info 命令实时更新节点拓扑信息
每隔 2 秒,每个哨兵节点会向 Redis 数据节点的 __sentinel__:hello 频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其他哨兵节点以及它们对主节点的判断。
这个定时任务可以完成以下两个工作:
- 发现新的哨兵节点:通过订阅主节点的
__sentinel__:hello了解其他的哨兵节点信息,如果是新加入的哨兵节点,将该哨兵节点信息保存起来,并与该哨兵节点创建连接。 - 哨兵节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
- 发现新的哨兵节点:通过订阅主节点的
每隔 1 秒,每个哨兵节点会向主节点、从节点、其余哨兵节点发送一条 ping 命令做一次心跳检测,来确认这些节点当前是否可达。
通过这个定时任务,哨兵节点对主节点、从节点、其余哨兵节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点失败判定的重要依据
4.1 基于 pub/sub 机制的哨兵集群组成
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是 发布/订阅 机制。
哨兵只要和主库建立起了连接,就可以在主库上发布消息了,比如说发布它自己的连接信息(IP 和端口)。同时,它也可以从主库上订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
在主从集群中,主库上有一个名为 “_ _sentinel_ _:hello“ 的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
举个例子,具体说明一下。
在下图中,哨兵 sentinel_26379 把自己的 IP(127.0.0.1)和端口(26379)发布到频道上,哨兵 26380 和 26381 订阅了该频道。那么此时,其他哨兵就可以从这个频道直接获取哨兵 sentinel_26379 的 IP 地址和端口号。通过这个方式,各个哨兵之间就可以建立网络连接,哨兵集群就形成了。它们相互间可以通过网络连接进行通信,比如说对主库有没有下线这件事儿进行判断和协商。
4.2 哨兵和从库的连接
哨兵除了彼此之间建立起连接形成集群外,还需要和从库建立连接。这是因为,在哨兵的监控任务中,它需要对主从库都进行心跳判断,而且在主从库切换完成后,它还需要通知从库,让它们和新主库进行同步。
哨兵是如何知道从库的 IP 地址和端口的呢?
这是由哨兵向主库发送 INFO 命令来完成的。
就像下图所示,哨兵 sentinel_26380 给主库发送 INFO 命令,主库接受到这个命令后,就会把从库列表返回给哨兵。接着,哨兵就可以根据从库列表中的连接信息,和每个从库建立连接,并在这个连接上持续地对从库进行监控。senetinel_26379 和 senetinel_26381 可以通过相同的方法和从库建立连接。

4.3 哨兵和客户端的连接
但是,哨兵不能只和主、从库连接。因为,主从库切换后,客户端也需要知道新主库的连接信息,才能向新主库发送请求操作。所以,哨兵还需要完成把新主库的信息告诉客户端这个任务。
在实际使用哨兵时,我们有时会遇到这样的问题:如何在客户端通过监控了解哨兵进行主从切换的过程呢?比如说,主从切换进行到哪一步了?这其实就是要求,客户端能够获取到哨兵集群在监控、选主、切换这个过程中发生的各种事件。此时,我们仍然可以依赖 pub/sub 机制,来帮助我们完成哨兵和客户端间的信息同步。
从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。
哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。(这里就不一一列出了)
知道了这些频道之后,你就可以让客户端从哨兵这里订阅消息了。具体的操作步骤是,客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。
举个例子,你可以执行如下命令,来订阅“所有实例进入客观下线状态的事件”:
SUBSCRIBE +odown
当然,你也可以执行如下命令,订阅所有的事件:
PSUBSCRIBE *
五、小结
Redis 哨兵是 Redis 的高可用实现方案:故障发现、故障自动转移、配置中心、客户端通知。
5.1 哨兵机制其实就有三大功能:
监控:监控主库运行状态,并判断主库是否客观下线;
选主:在主库客观下线后,选取新主库;
通知:选出新主库后,通知从库和客户端。
5.2 一个哨兵,实际上可以监控多个主节点,通过配置多条 sentinel monitor 即可实现。
5.3 哨兵集群的关键机制:
- 哨兵集群是基于 pub/sub 机制组成的
- 基于 INFO 命令的从库列表,这可以帮助哨兵和从库建立连接
- 基于哨兵自身的 pub/sub 功能,这实现了客户端和哨兵之间的事件通知
Sentinel 与 Redis 主节点 和 从节点 交互的命令,主要包括:
| 命令 | 作 用 |
|---|---|
| PING | Sentinel 向 Redis 节点发送 PING 命令,检查节点的状态 |
| INFO | Sentinel 向 Redis 节点发送 INFO 命令,获取它的 从节点信息 |
| PUBLISH | Sentinel 向其监控的 Redis 节点 __sentinel__:hello 这个 channel 发布 自己的信息 及 主节点 相关的配置 |
| SUBSCRIBE | Sentinel 通过订阅 Redis 主节点 和 从节点 的 __sentinel__:hello 这个 channnel,获取正在监控相同服务的其他 Sentinel 节点 |
Sentinel 与 Sentinel 交互的命令,主要包括:
| 命令 | 作 用 |
|---|---|
| PING | Sentinel 向其他 Sentinel 节点发送 PING 命令,检查节点的状态 |
| SENTINEL:is-master-down-by-addr | 和其他 Sentinel 协商 主节点 的状态,如果 主节点 处于 SDOWN 状态,则投票自动选出新的 主节点 |
5.4 建议
尽可能在不同物理机上部署 Redis 哨兵所有节点
Redis 哨兵中的哨兵节点个数应该为大于等于 3 且最好为奇数
推荐奇数个节点,主要是从成本上考虑,因为,集群中,半数以上节点认为主节点故障了,才会选举新的节点。这样的话奇数个节点和偶数个节点允许宕机的节点数就是一样的,比如 3 个节点和 4 个节点都只允许宕机一台,那么为什么要搞 4 个节点去浪费服务资源呢?但是 4 个节点的性能和容量肯定是更高的哈。
References
- 《Redis 开发与运维》
- 《Redis 核心技术与实战》
- https://redis.io/topics/sentinel
- https://www.cnblogs.com/kismetv/p/9609938.html